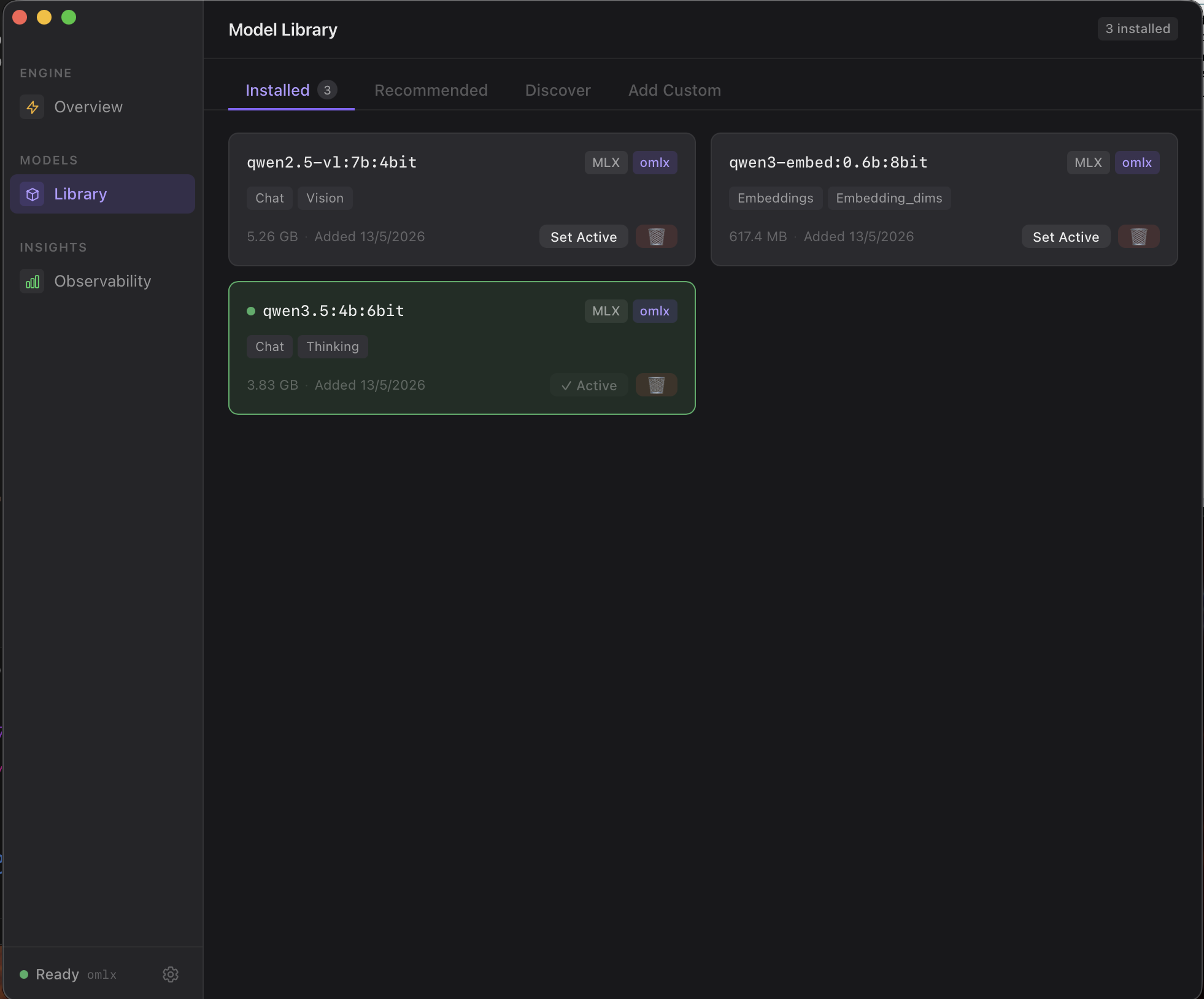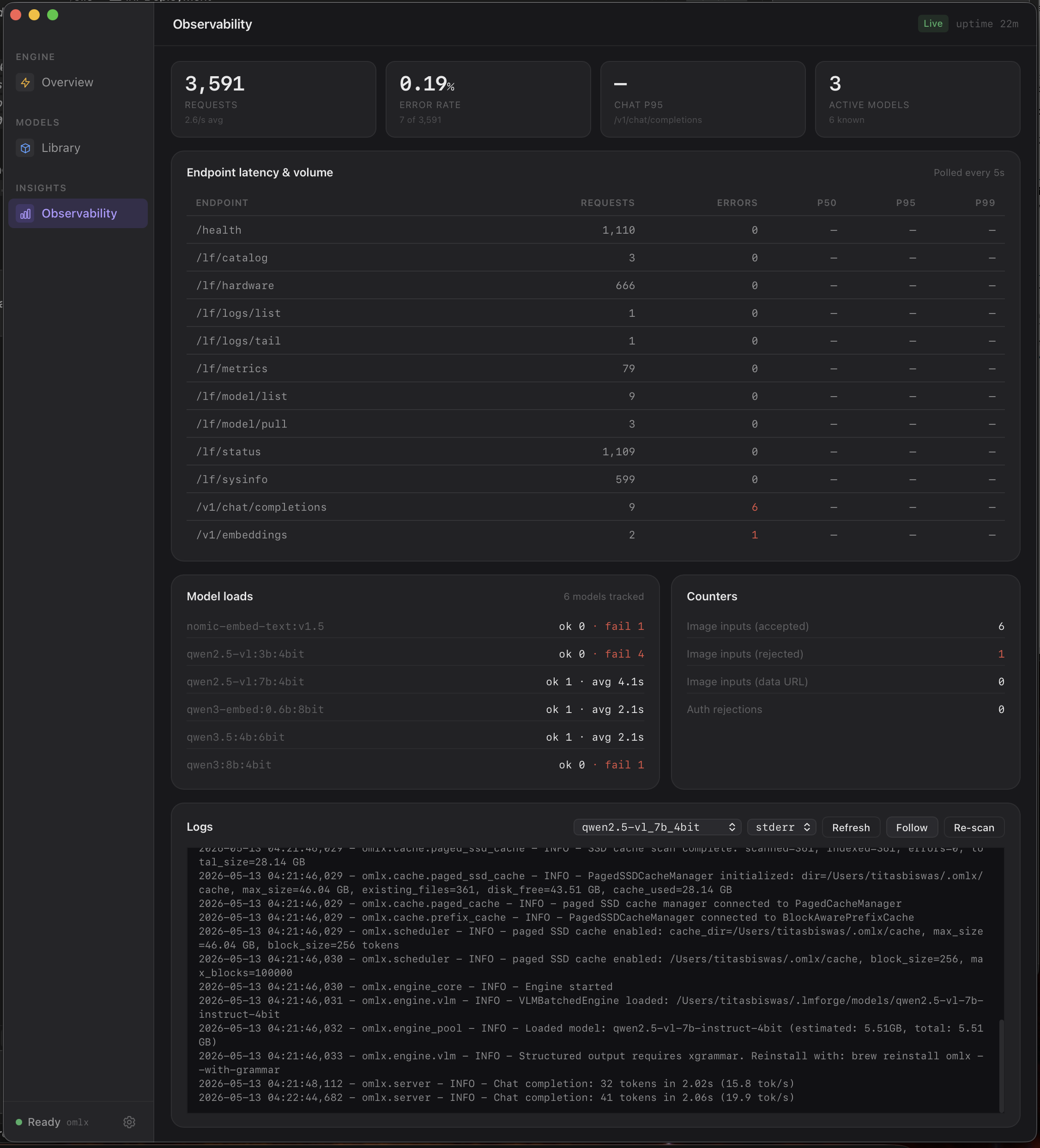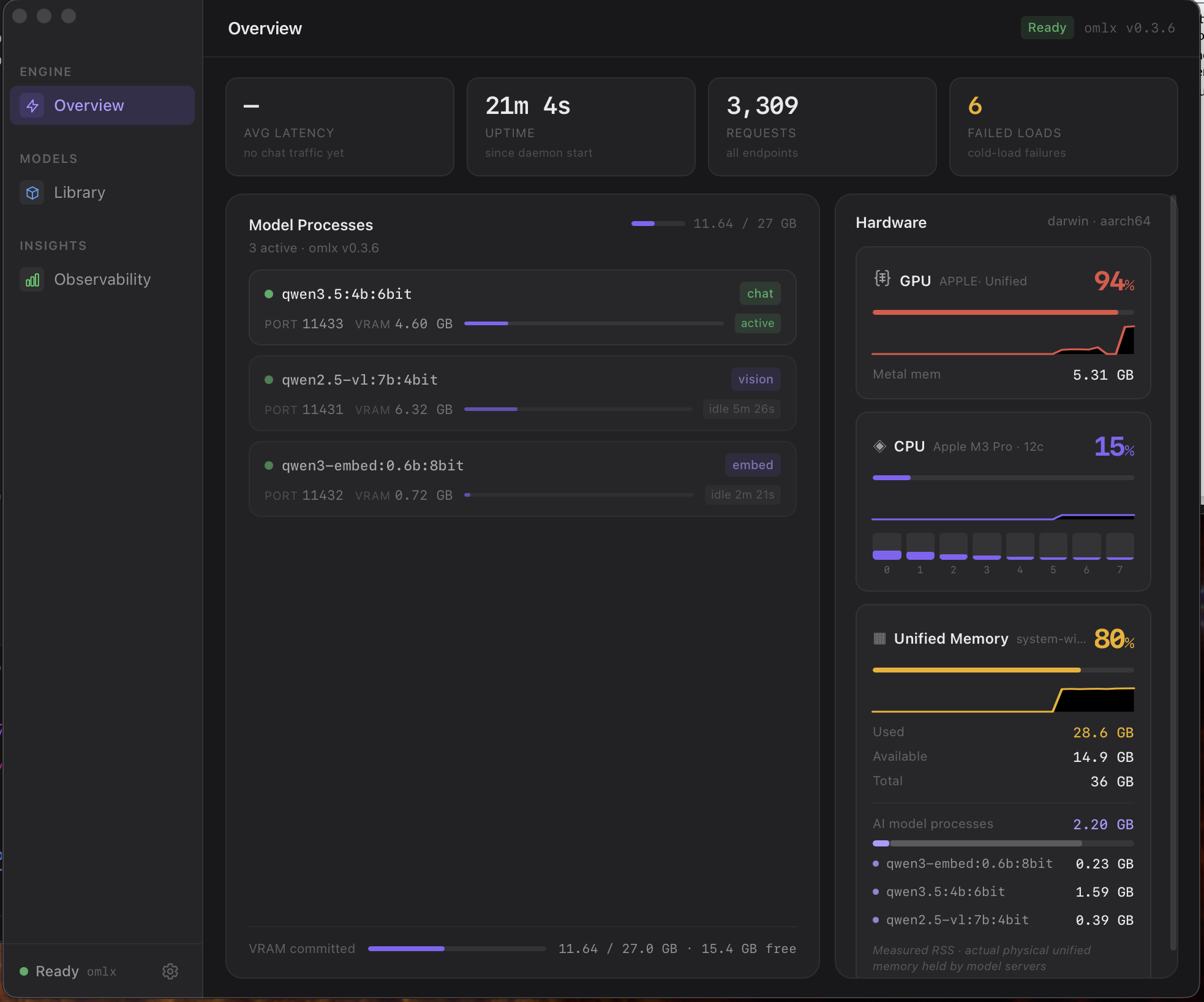
Hardware-aware engine selection
Probes the host at startup and picks the best inference backend automatically — no engine config to maintain.
Apple Silicon → oMLX (Metal/MLX, OpenAI-compatible server). Linux NVIDIA → SGLang (CUDA, high-concurrency). Windows NVIDIA, ARM Linux, or CPU-only → llama.cpp with auto -ngl tuning. Engine choice is hardware-driven, not user-configured; users get one OpenAI API regardless of what's underneath.